Prompting Without Prompt Engineering
One thing that often gets overlooked about large language models (LLMs) is that they are primarily trained on English content and designed with English-language use in mind. Beyond the language itself, there's a cultural assumption baked into how these tools expect to be used: that users will write prompts that are direct and highly specific.
Even as a native English speaker, I've had to think carefully about how to write a good prompt to get the result I'm looking for. When you consider the iterative nature of prompt engineering, the goal is always to get a useful output in as few attempts as possible.
That said, watching users interact with these tools - particularly those who don't work primarily in English - it becomes clear that prompt engineering can be a genuinely frustrating experience. The most effective strategy is to state your end goal in clear, direct language. For example, "make this house look nicer" will produce far weaker results than "replace the lower half of the exterior walls with white tile, add a glass carport over the driveway, and change the roof to blue ceramic tiles." For many people, writing that kind of explicit instruction doesn't come naturally. The way we phrase requests in everyday conversation, especially across cultures where indirect communication is the norm, often doesn't translate well into effective prompts.

To address this, ArchiX has introduced an option that makes the experience significantly smoother. In our app, users can select a predefined action from a dropdown - Add, Replace, or Remove - and then fill in a few basic fields. This gives the AI exactly what it needs to understand what to change and how to change it, without requiring the user to construct a detailed prompt from scratch. Our model interprets this structured input more accurately across multiple languages, and users consistently reach their desired result in fewer attempts.

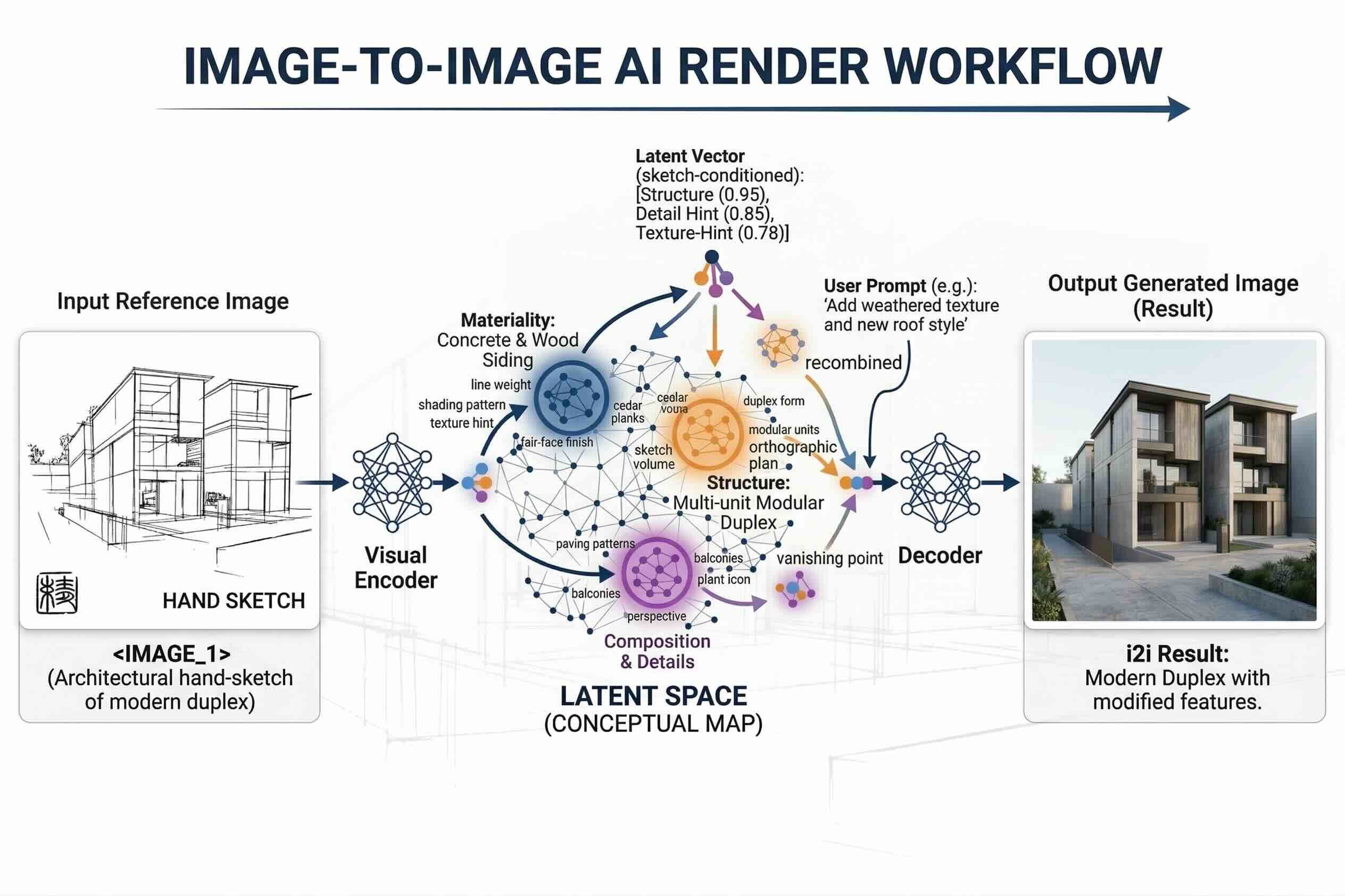
To understand why this works, it helps to know how AI image editing actually functions under the hood. When you submit a text prompt, the AI performs what's called latent mapping: it breaks the image down into identifiable elements - cars, windows, doors, trees, and so on. The organized, AI-readable version of the image that results from this process is known as the latent space. The AI then cross-references this latent space against your text prompt to determine which part of the image you want to change and how. Once the target area is identified, a layering cycle begins, gradually shifting that area toward the intended outcome described in the prompt.
What makes our promptless prompt tool effective is that the latent space targeting is already defined in the background. The user's input only needs to supply the final piece: what the target is and what should be done to it. For anyone who isn't already comfortable with prompt engineering, this makes the whole experience considerably faster and less intimidating.